Résumé
Lorsque l’on parle de résolution de labyrinthe, il peut s’agir de plusieurs problèmes. Tout d’abord il faut spécifier les caractéristiques du labyrinthe étudié ainsi que le type d’algorithme utilisé pour résoudre celui-ci. Il faut aussi spécifier ce que nous souhaitons également obtenir comme résultat. Le type d’algorithme est-il complet ou incomplet ? La solution trouvée est-elle la meilleure ? La plus courte ? La plus rapide ?
Pour ce faire, une multitude d’algorithmes existent tel que l’algorithme du mur droit, l’algorithme du retour sur sa trace, l’algorithme du plus court chemin ou des plus courts chemins. Chacun de ces algorithmes dispose alors de sa propre fiabilité et rapidité comme l’indique le tableau du site astrolog.org , mais aussi de sa propre complexité.
Les différents types d’utilisation définiront donc dans quel cas il vaut mieux utiliser tel ou tel algorithme. En effet, le labyrinthe n’est pas uniquement un jeu se trouvant dans le programme télévisé. Un labyrinthe est avant tout un arbre, et un arbre est un graphe. Par ces équivalences, la résolution de labyrinthe et donc de graphes permet de résoudre de grosses problématiques d’intelligence artificielle dans de nombreuses applications.
Ainsi, le cadre d’étude sera limité à :
- Dimension: 2D
- Hyper dimension: Non-HyperMaze
- Topogie: Normal
- Técélation: Carré
- Routing: Normal
- Texture: uniforme
Dans quelles mesures la résolution de labyrinthe est-elle essentielle à la modélisation et à la résolution de grandes problématiques d’intelligence artificielle ?
Afin de traiter au maximum cette problématique, notre étude se consacrera à trois algorithmes mélangeants approche complète et incomplète.
Principes
Un labyrinthe est une modélisation de graphes. Sa résolution permet donc aussi de résoudre d’autres problématiques qui peuvent être modélisées par des graphes. Ainsi, les algorithmes destinés dans un premier temps à la résolution d’un simple jeu peuvent en fait être utilisé pour des questionnements beaucoup plus complexes. La figure ci-dessous nous permet notamment d’illustrer ces propos :
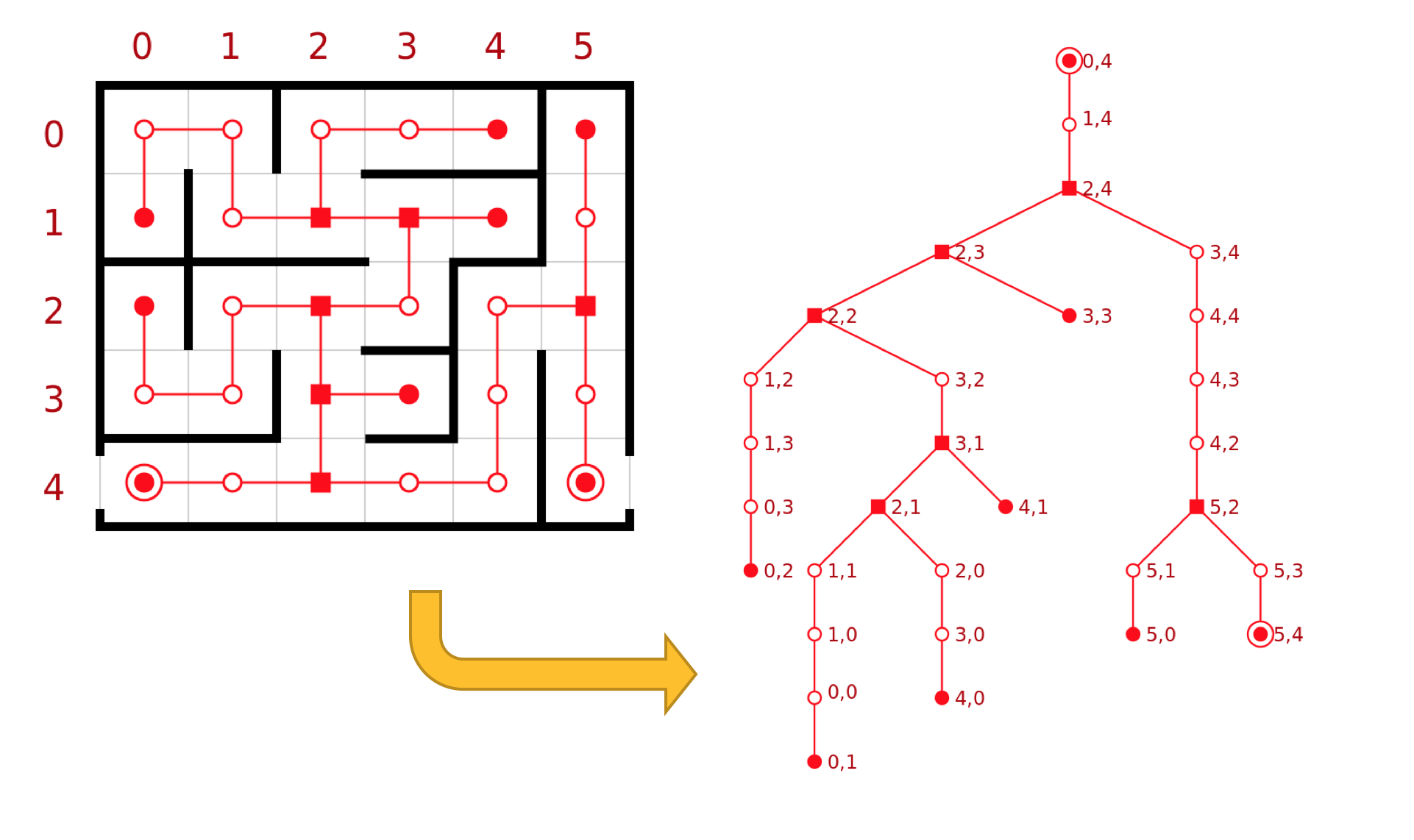
Sources image : wikipédia
Origines
L’origine de la construction de labyrinthe remonte à l’Égypte ancienne il y a plus de 4000 ans. Les tombeaux des pharaons étant alors construits de façon à ce que des centaines de salles et de couloirs soient construits au cœur des pyramides. Durant près de 2000 ans égyptiens et grecques construisirent des labyrinthes plus ou moins imposants que ce soit dans les pyramides ou dans les cités antiques telles qu’Alexandrie et Knossos.
Aux alentours de la même période, en Crète, fut érigé un labyrinthe connu sous le nom de Labyrinthe de Crète ou Seven-circuit. Celui-ci comportait aussi plusieurs centaines de salles mais consistait en fait en un labyrinthe unicursale tel que celui-ci :

Sources image : wikipédia
De manière générale les labyrinthes furent utilisés de façon à empêcher un étranger de pénétrer dans un lieu particulier.
Dès la fin du 19eme siècle, c’est l’architecte Charles-Pierre Trémaux qui a mis en place un des premiers algorithmes de résolution de graph en profondeur et qui fut un précurseur en termes de recherche sur ce sujet.
Finalement c’est depuis l’apparition des premiers calculateurs que les scientifiques se sont mis à rechercher puis implémenter des algorithmes plus complexes. En effet ce n’est que très récemment que les scientifiques commencèrent à chercher comment résoudre de manière efficace et rapide les labyrinthes.
Principes
Algorithme de Pledge
Principes :
Cet algorithme repose sur le très simple mais très connu suiveur de mur, il s'agit même d'une extension de ce dernier. Pour commencer l'algorithme de suivi du mur consiste tout simplement à choisir un mur (droite ou gauche) et à le suivre sans lâcher le contact.
Comme je l'ai dit plus tôt on peut voir l'algorithme de Pledge comme une extension du suiveur de mur, en effet, nous ne choisissons ici non pas un mur mais une direction. En d'autres termes arrivé à une intersection si le choix de la direction est disponible, nous prenons ce choix.
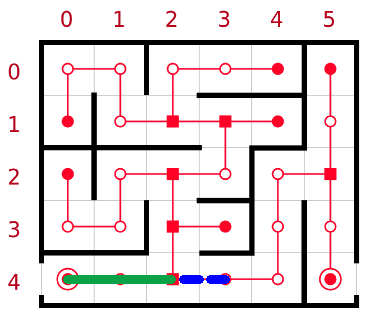
Source image : wikipédia , modifiée par le groupe.
Ajouté à cette hypothèse de base, nous introduisons le fait de suivre un mur (droite ou gauche) en cas de non possibilité de la direction choisie. Par exemple, si nous arrivons à une intersection dite bloquante (la direction choisie étant la droite) et que nous avons choisi de suivre le mur droite il se passera le cas suivant:
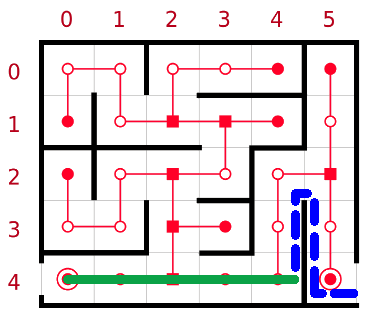
Source image : wikipédia , modifiée par le groupe.
Ici le cas était parfait et il peut arriver que le chemin effectif soit plus long. Reprenons l'exemple et choisissons de suivre le mur de gauche. Mais sur l'ensemble de règles que nous possédons déjà nous allons en ajouter une dernière: si nous somme en cas de suivit de mur nous allons reprendre le suivit de direction dès que nous serons revenu sur cette dernière:
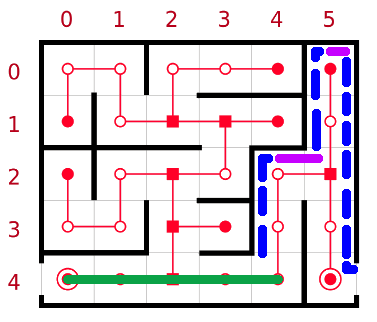
Source image : wikipédia , modifiée par le groupe.
Ainsi ici nous avons le fonctionnement de suivit de mur en bleu et celui de suivit de direction en violet. Sur cet exemple nous voyons que le chemin suivit n'est pas différent avec la nouvelle règle ajoutée cependant nous pourrons voir sur l'exemple d'application que cette dernière règle peut être très utile. Voici donc en résumé l'algorithme de Pledge:

Exemple d'utilisation :
Nous avons vu que cet algorithme est capable de résoudre des labyrinthes où les angles sont toujours droit. Cependant cet algorithme de par sa simplicité est notamment utilisé en robotique pour des applications pouvoir contourner les obstacles. Voici un exemple pour un obstacle complexe avec des angles non droits:
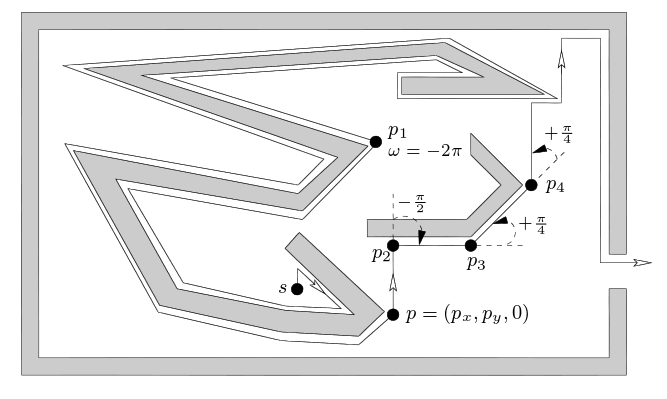
Nous voyons ici que l'algorithme de Pledge nous sert à sortir de cet espace clos même s'il ne le fait pas de la manière la plus optimale, il est tout de même capable de se sortir de ce problème.
Critique :
Cet algorithme a cependant quelques limites. La toute première est de ne pas "retenir" le chemin emprunté. En effet, nous ne faisons que suivre un panel d'instructions basique et pouvons même revenir sur nos pas sans nous en rendre compte. De plus comme cet algorithme repose sur une heuristique, il se peut que cette dernière soit erronée, ainsi nous pouvons parfois nous résoudre à parcourir tout le labyrinthe avant de trouver la sortie et donc la solution. Il existe aussi certaines limites "spéciales" à cet algorithme. En effet certains cas de labyrinthes hors du cas d'étude nous montre que cet algorithme va pouvoir boucler sans trouver de solutions ni même revenir au départ. Il s'agit de labyrinthe dans lesquels la sortie et l'entée se trouvent au milieu du labyrinthe:

On voit ici le parcours réalisé avec l'algorithme Pledge en orange avec l'entrée en rouge et la sortie en jaune. Pour ce cas-ci l'algorithme va boucler en permanence sans en sortir et comme l'algorithme ne se souvient pas de son chemin il ne se rend même pas compte de ce phénomène.
Algorithme du retour sur trace (Recursive Backtracking)
Principes :
Cet algorithme peut être comparé à une tête chercheuse intelligente. En effet, celle-ci teste des chemins tout en mémorisant sa trace afin de pouvoir retourner au dernier point intéressant, c’est-à-dire la dernière intersection. Cette méthode permettra forcement de trouver une solution au problème dans un arbre.
L’algorithme marquant sa trace, il prendra donc uniquement des directions et des chemins non visités précédemment. Cette méthode permettra donc outre passer les problèmes de boucles dans un labyrinthe (là où d’autre algorithmes restent bloqués). Les boucles sont caractéristiques des graphes, ce qui les distingue des arbres. Ainsi, cet algorithme peut aussi bien résoudre des problèmes d’intelligence artificielle schématisée en graphe ou arbre.
Cependant, l’algorithme possède des limites. Dans le cas d’un problème comportant une ou plusieurs boucles, la résolution sera incomplète. Ainsi dans un labyrinthe comportant une boucle, il y aura forcément une portion visitée, donc toutes les solutions ne seront pas testées. Ainsi, pour la recherche du plus court chemin, cet algorithme n’est pas le plus fiable.
Description algorithme:

|
Schématisation des étapes de l’algorithme :
|
ETAPE 1
- Départ : direction droite choisie - Chaque case parcourue est mémorisée et marquée par un « o » |
ETAPE 2
- Rencontre de la première intersection (« i ») - 2 choix possibles, ces choix peuvent être aléatoires ou basés sur une heuristique - Choix de la direction droite |
| ETAPE 3
- Parcours de 4 cases vers la droite puis arrivée dans une voie sans issue - Retour en arrière vers la dernière intersection connue - Elimination de la direction précédemment choisie - Choix d’une direction possible, ici en bas |
ETAPE 4
- L’algorithme continue ensuite comme ça jusqu’à la sortie |
Sources images : Groupe, basé sur notre comprehension de l'algorithme.
Exemple de resolution d'un labyrinthe avec l'algorithme du backtracking :
Exemple d'utilisation :
L’algorithme du backtracking est utilisé pour la résolution de problèmes à satisfaction de contraintes. On peut trouver des utilisations basiques pour la résolution de sudoku par exemple.
Cet algorithme peut aussi être utilisé pour une intelligence artificielle associée au jeu d’échec. Il permet ainsi d’obtenir un arbre des solutions possible pour un problème comme les huit ou quatre reines. Remy Duperray nous décrit les étapes a suivre sur ce document.
Source : Wikipédia.
Critique :
Complexité algorithmique:
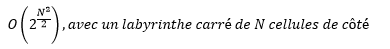
Pour arriver à ce résultat nous avons sollicité l’aide de l’intervenant M. Saïdi dans le cadre du projet. Pour exprimer la complexité de cet algorithme nous sommes partis de la formule empirique :
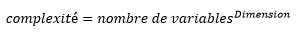
Appliqué à la résolution des labyrinthes :
- Nombre de variables: ¬ directions possibles Ici sur chaque cellule, 4 directions possibles. On peut simplifier à 2 directions disponibles en moyenne, en enlevant la direction d’où l’on vient et un mur.
- Dimension: dimension de l’espace du problème, ici le nombre cellules du labyrinthe N^2 . En partant de la base que la moitié des cellules du labyrinthe sont des murs on trouve (N^2)/2
On peut dire que cette algorithme est modérément coûteux en puissance de calcul, mais très peu coûteux en mémoire (on garde en mémoire la «stack» du chemin jusqu’à la dernière intersection connue.)
Algorithme du plus court chemin (shortest path)
A la base des algorithmes de recherche de plus court(s) chemin(s) on retrouve trois types de recherches basiques, le parcours en profondeur (depth-first search), le parcours en largeur (breadth-first search) et le meilleur premier (best-first search). Dans le cas de la résolution de graphe, ces algorithmes devront se rappeler chaque sommet dans lesquelles ils seront précédemment passés pour éviter de créer une boucle. Le depth-first entreprend d'explorer une voie en profondeur avant de rebrousser chemin pour explorer un autre chemin tandis que le breadth-first commence à la racine et on explore les voisins directs puis les voisins directs de ses voisins. Le Best-first quant à lui explore le graph en explorant le nœud qui semble le plus prometteur selon une règle (heuristique) que l’on aura mise en place. Dans notre cas d'étude nous nous appuierons sur deux exemple d'algorithme qui sont Dijkstra, qui s'appuie sur un algorithme de calcul de métrique, et A* qui s'appuie sur les algorithmes de Dijkstra tout en reprenant l'heuristique d'un Best-first.
Dijkstra
Principes :
Cet algorithme est utilisé typiquement pour trouver un chemin entre les sommets d’un graph. Le poids du chemin entre deux sommets est la somme des poids des arrêtes qui le composent. Voici un exemple: on veut aller du point A au point J et on connaît les distances entre les différents points du graph. On voit sur la figure 1 que tous les points qui ne sont pas voisin direct de A sont à une distance +∞ de lui.

L’algorithme fait donc emprunter le chemin entre A et B car c’est le plus court et calcule le chemin entre B et ses voisins (ici F en figure 2).
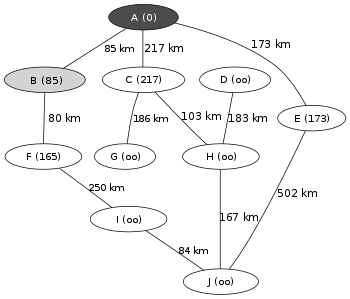
Le chemin vers F étant toujours plus court que celui de A vers C ou de A avers E l’algorithme continue et calcul le chemin entre F et ses voisins directs (figure 3).
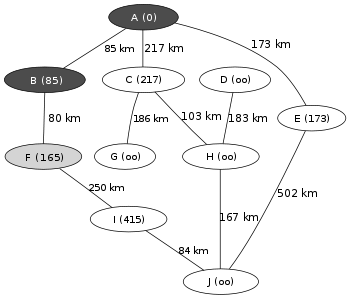
Cette fois-ci les chemin AE (173km) est plus court que le chemin AI (415km). L’algorithme va donc déterminer la distance entre E et ses voisins. Puis ainsi de suite jusqu’à trouver le plus court chemin vers J.
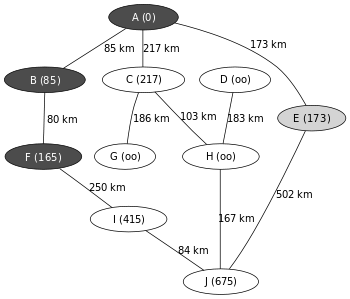
|
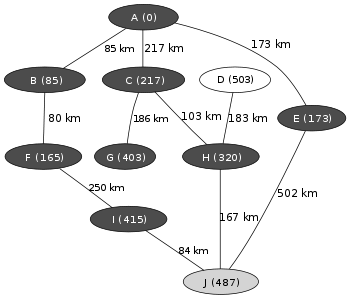
|
Exemple d'utilisation :
Un exemple d'utilisation largement usé est le protocole réseau OSPF (Open Shortest Path First). Le graphe est symbolisé par le réseau de routeur qui représente les nœuds. La distance que doit parcourir l'information d'un routeur à un autre est la métrique. Chaque routeur calcul par rapport à ses voisins la distance que les séparent des autres. Ainsi lorsque l'information doit se déplacer d'un routeur A à un routeur B, Dijkstra calculera le coût le moins cher pour trouver le plus court chemin.
Critique :
Dijkstra trouvera tous les chemins et sera gourmand en calcul et mémoire. Pour ce faire, nous pouvons décider d'arrêter le calcul une fois le chemin le plus court trouvé.
A* search algorithm
Principes :
Cet algorithme est une extension de celui de Dijkstra. Il a été créé pour que la première solution trouvée soit l’une des meilleures (si ce n’est la meilleure). La vitesse de calcule est privilégiée sur l’exactitude des résultats. De plus cet algorithme s'appuie sur une estimation heuristique qui estime le coût entre un état et un état solution. Le chemin final calculé sera celui du coût le plus faible. En général une bonne heuristique est d’introduire la distance euclidienne entre deux points dans un espace normé. Prenons appuie sur un exemple, lors de la résolution d’un labyrinthe dont on pense que la solution se trouve en bas, on peut ajouter cette condition comme heuristique dans l’algorithme. Alors que l’algorithme de Dijkstra fera des recherches sur tous les points dans un rayon circulaire fixe (de centre le point de départ), A* va explorer en priorité le chemin d’en bas à chaque intersection. On continue à faire ça tant que la route le permet et on revient en arrière si on tombe sur une impasse. Dans cet algorithme les nœuds sont comparés par rapport à l’heuristique introduite.
Exemple d'utilisation :
Prenons l'exemple d'une application GPS, la distance euclidienne est déterminée grâce à la position GPS du point de départ (A) au point d’arriver (B). Pour ce cas nous considérons un graphe orienté qui est une carte routière (A* s’applique aussi très bien à un graphe non orienté). Ensuite nous représentons chaque intersection comme un nœud de notre arbre et chaque route entre deux intersections comme une arrête. Dans le cas idéal la route est sans obstacle et le chemin est direct du point A au point B. Dans la réalité il y a des obstacles ou des culs-de-sac (graphe connexe non orienté et non parfait), dans ce cas nous calculons pour chaque nœud parent le coût de la fonction heuristique et le coût de déplacement qui est nommé à un nœud fils de la façon suivante : F(n) = Heuristic(n) + stepcost(p,n) où n: nœud fils et p: nœud parent Pour qu’un déplacement s’effectue il faut que l’heuristique du nœud parent ne surestime jamais le coût d’une étape à une autre, de ce fait nous avons : H(p) ≤ F(n) Autrement dit l’estimation sur un A* pour se déplacer d’un nœud parent à un nœud enfant se fait sur la moins pire des solutions en termes de coût, donc celle qui valorise le mieux notre heuristique. On pourra ensuite parler d’une heuristique consistante si elle améliore la recherche de solution pour un grand nombre de cas.
Critique :
A contrario de Dijkstra, l’heuristique qu’utilise A* lui permet d’optimiser les temps de calcul en s’appuyant sur les propriétés d’un problème. Dans la majorité des cas A* est bien plus rapide que Dijkstra, notamment voir cette vidéo très intéressante en termes de coût de calcul avec l’introduction d’une amélioration de Dijkstra qui est une version concourante de cette dernière et permet de faire des calculs simultanés. Aussi cet algorithme n’est pas parfait comme on peut le voir dans l’exemple suivant :
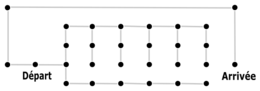
Ici on applique l’heuristique suivante : La sortie se trouve à droite. A* va donc explorer toute la partie droite du labyrinthe avant de revenir sur ses pas, aller à gauche et enfin trouver la sortie.
Utilisations
Critique
La résolution de labyrinthe peut trouver des applications diverses et variées. Mais la principale limitation repose sur le fait qu’elle ne résout que des problèmes schématisés (que ce soit un maillage ou un arbre.)
Par la suite, suivant le type de schéma à résoudre et les contraintes imposées il conviendra de choisir l’algorithme le plus pertinent. Est-ce que je recherche toutes ou une seule solution possible à mon problème (solution complète/incomplète), quelles ressources je dispose en terme de calcul et de mémoire (sélectionner la complexité adaptée). Tels sont les critères permettant de choisir un algorithme de résolution approprié à un problème.
Son présenté ci-dessous les limites de chaque algorithme détaillé précédemment :
| Pledge | Retour sur trace (Backtracking) | Best-first | Dijkstra | A* | |
| Type de labyrinthe | Graphes | Graphes | Graphes connexes | Graphes connexes | Graphes connexes |
| Complet/Incomplet | Incomplet | Incomplet | Incomplet | Complet | Complet |
| Complexité | O(n²) | O(2^(n²/2)) | O(m^p) (avec p la profondeur maximale de la sortie) | O((m+n)*ln(n)) m arcs et n nœuds.Complexité linéarithmique. | O((m+n)*ln(n)) (dans le pire des cas = complexité de Dijkstra) |
| Espace mémoire | Très faible | faible | faible | 3 listes:
|
Identique à Dijkstra mais en moyenne moins gourmand en ressources mais plus gourmand en calcul |
| Rapidité | Rapide mais dépend de l'heuristique | Rapide | Rapide | Rapide | Rapide |
| Solution obtenue | Une solution non garantie | Une solution parmis toute les autres | Une solution parmis toute les autres | La solution la plus rapide | La solution la plus rapide |
En lien avec l'IA nous pouvons mentionner qu'un robot autonome est bien souvent amené à devoir se déplacer dans un environnement intérieur ou extérieur. Admettons qu'il connaisse la topologie de la pièce suite à une cartographie de type SLAM ou un fichier pré-chargé dans son environnement. Ce robot dispose de plusieurs algorithmes de calcul de plus court chemin comme le Best-First, Dijkstra ou encore A* mais lequel choisir? A l'inconvénient d'un Best-First (Depth-First ou Breadth-First aussi bien), Dijkstra et A* utilisent la notion de poids (métrique) entre deux nœuds. De ce fait ce sont des algorithmes d'explorations plus rapide en moyenne car ils évitent des calculs supplémentaires. Aussi ces deux derniers s'appliquent à l'exploration de graphes contrairement aux autres plus appropriés aux arbres. Comparons maintenant A* et Dijkstra, Dijkstra ne disposant pas d'heuristique va explorer une carte en cercle et calculer tous les coûts de déplacement (on a dit qu'il était complet) tandis que A* se focalise sur le but à atteindre. La seule limite de A* est de se retrouver avec une heuristique qui s'annule, dans ce cas-là il reproduira l'identique d'un Dijkstra. A défaut d'être sa limite c'est aussi sa plus grande force qui participe à l'amélioration de son efficacité (calcul d'une distance euclidienne, distance de Manhattan...). En terme de calcul cependant, A* perd beaucoup de temps à ordonner ces listes et aussi dans le calcul de son heuristique (nécessite des faire des calculs arithmétiques). De façon générale, A* est quand même bien plus rapide en temps que Dijkstra.
Pour illustrer nos propos voici une image montrant un robot calculant son chemin apres l'avoir cartographié en SLAM. Il quadrille l'espace l'entourant afin de pouvoir calculer le meilleur chemin (en vert sur l'illustration). Le fait de quadriller la zone permet de faire comme si la carte n'était qu'en fait qu'un grand labyrinthe. Sans les algorithmes d'intelligence artificielle de type A* ou Dijktra, le robot ne serait pas capable de calculer son itinéraire.
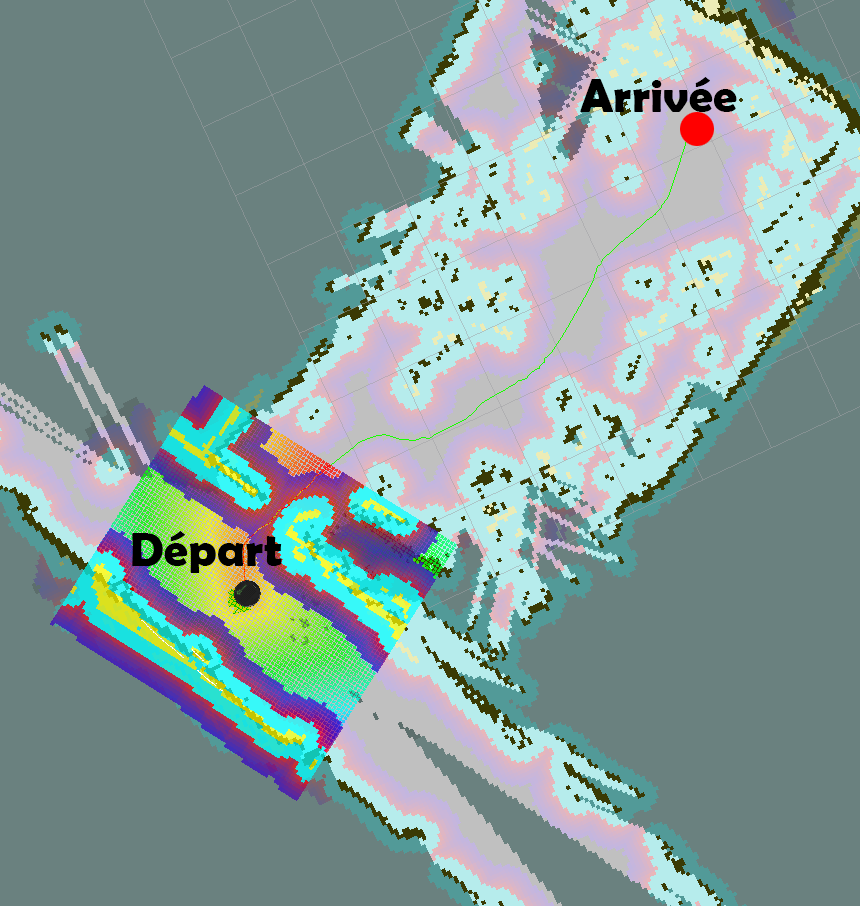
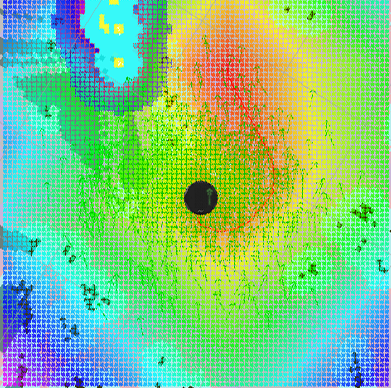
Source : screenshot TP robotique Romain Casery, B120
Enfin, le cadre d’étude étude a été fixé ici à un type précis de labyrinthe. Cependant l’univers des labyrinthes est relativement vaste, en faisant varier certains paramètres comme la topologie, la técélation ou la texture d’un labyrinthe nous nous retrouvons face à un nouveau type de problème nécessitant de nouveaux algorithmes mais pouvant schématiser de nouveaux problèmes d’intelligence artificielle.
Bibliographie
Notre recommandation : mb2014: Mike Bostock, June 26 2014 :Visualizing Algorithms
am2011: Auteurs Multiples, 2011: Algorithms Unplugged, Revue, Springer-Verlag
am2015: Auteurs Multiples, last modified June 2015: Wikipedia Backtracking Wikipédia, Backtracking
am2015: Wikipédia, A* search algorithm
am2015: Wikipédia, Dijkstra algorithm
am2015: Wikipédia, SLAM: Simultaneous Localization And Mapping
bbtkel2007: Bernd Brüggemann, Tom Kamphans et Elmar Langetepe, 2007: Leaving an Unknown Maze with One-Way Roads,Collection of Abstracts 23rd European Workshop Computer Geometry
cb2013: Christopher Berg, The History of Mazes and Labyrinths
cd2014: Carsten Dominik et redblobgame, Implementation of A*
dm2015: Didier Müller, 2015: L'informatique au lycée
ej2011: El Jj, 2011: Le labyrinthe dont vous etes le heros
tkel2004:Tom Kamphans et Elmar Langetepe, 2004: The Pledge Algorithm Reconsidered under Errors in Sensors and Motion, Approximation and Online Algorithms, Springer-Verlag
wdp2015: Walter D. Pullen, 2015: Think Labyrinth: Maze Algorithms Maze Classification
am2015: Auteurs Multiples, SLAM: Simultaneous Localization And Mapping